What does a good score look like?
These figures show the noise floor of the benchmark itself — i.e., the gap you observe when comparing one half of real Reddit data to the other half. Any model's score should be read against this floor. These figures are not part of the leaderboard; they characterise the measurement.
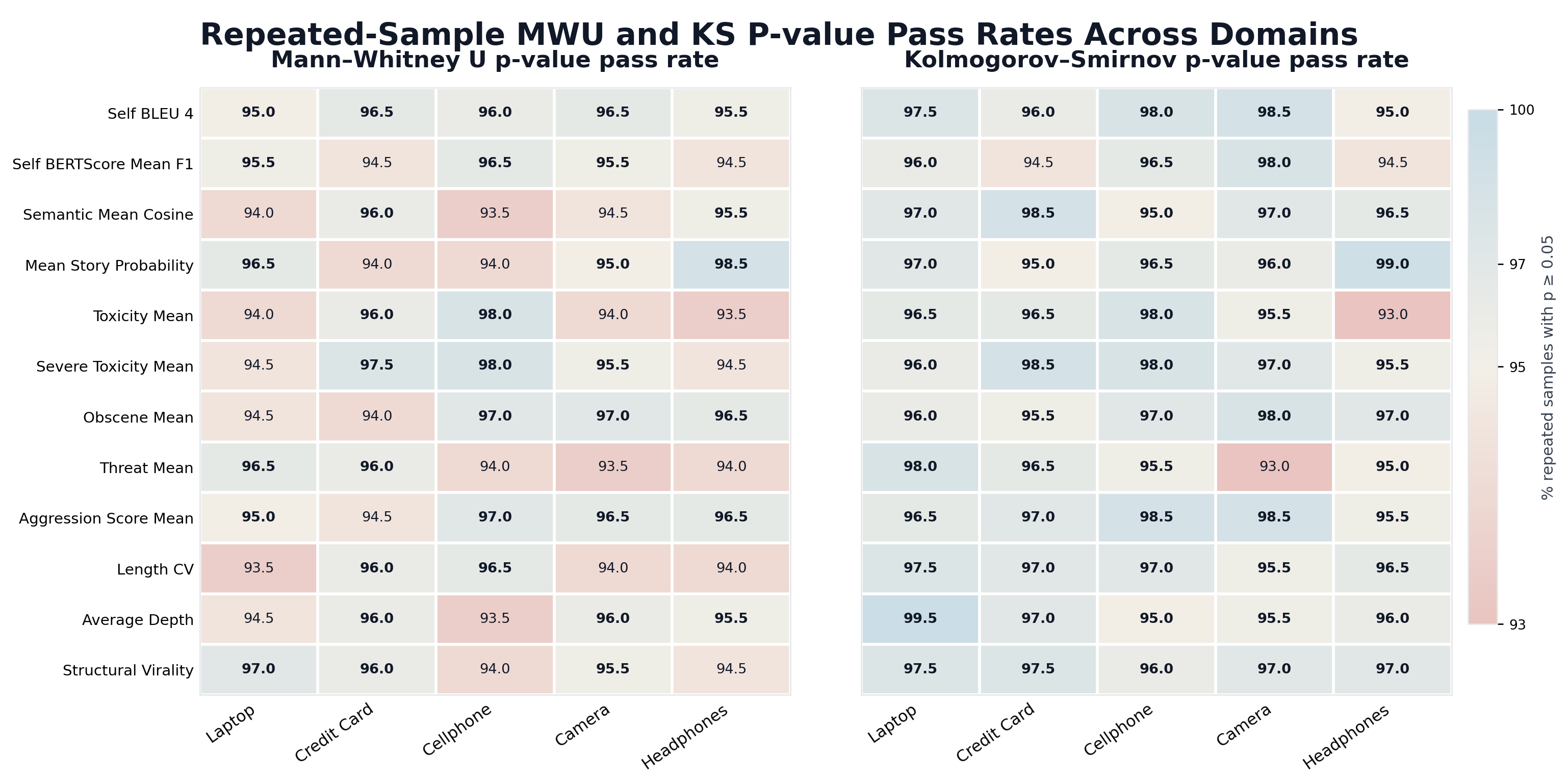
Repeatedly drawing two equal-sized samples from the real distribution and running Mann–Whitney U / Kolmogorov–Smirnov: ≈95% of comparisons return p > 0.05, which is the false-positive rate we should expect by construction. This is the "100% match" line that no model has approached.
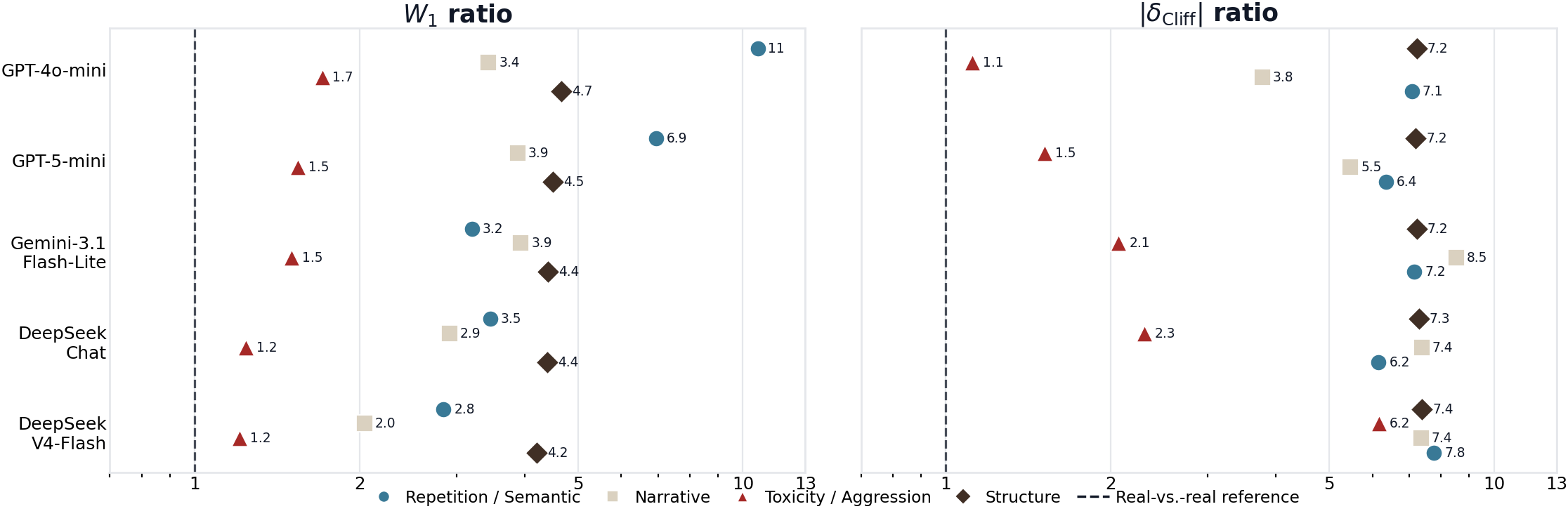
For each family, the dotplot shows the ratio of a model's average W1 (and |δ|) to the real-vs-real baseline. A ratio of 1.0 would mean a model is indistinguishable from sampling more real data; current models sit at 2×–11× the floor, with the largest gaps on Structure and Repetition.